I’ve been testing GPTHuman AI for content review and I’m not sure if I’ve configured it correctly or if I’m using the right prompts. Some outputs feel inconsistent and I can’t tell whether it’s my setup, the model behavior, or user error. I need help understanding how to properly review and optimize my GPTHuman AI results so I can rely on it for accurate, high‑quality feedback.
GPTHuman AI Review
I spent some time messing with GPTHuman after seeing the claim “The only AI Humanizer that bypasses all premium AI detectors.” Short version of my experience: that line did not match what happened on my screen.
I followed the tests shown here:
Then I re-ran my own set with fresh text.
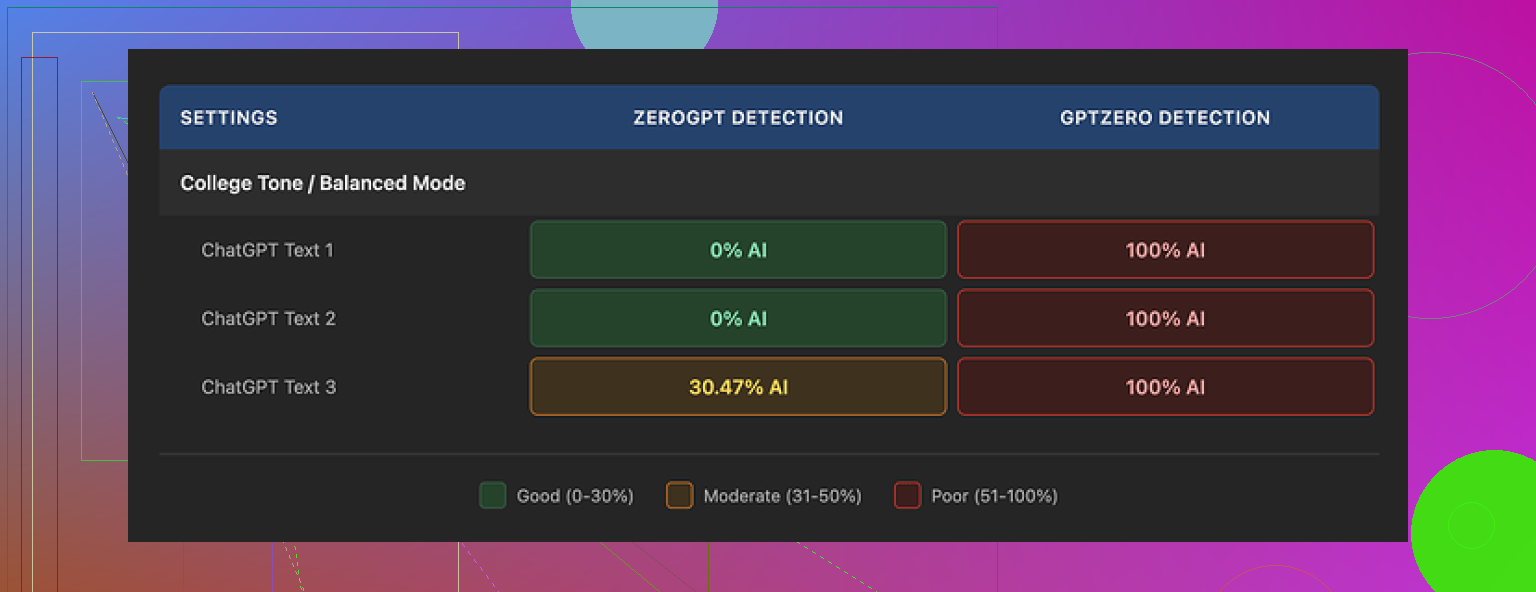
Detector results
I pushed three different GPT outputs through GPTHuman, then sent those results to two detectors:
-
GPTZero
• All three GPTHuman outputs came back as 100% AI. No edge cases, no “mixed” flags.
• I tried varying topics and styles, same story. -
ZeroGPT
• Two of the three samples passed as 0% AI.
• The third one was flagged around 30% AI probability. Not “fully human,” not “fully AI.”
On GPTHuman’s side, the built-in “human score” looked great. High “pass” indicators across the board. The issue is those internal scores did not line up with what GPTZero or ZeroGPT reported. If you rely on external detectors, their internal meter feels misleading.
Writing quality
The output looks neat at first glance. Paragraph spacing is fine, no obvious formatting mess. Then you read slower and the cracks show up.
Stuff I kept seeing:
• Subject verb disagreements
Example pattern: “The results shows” or “The tools are gives”
• Sentence fragments
Half a thought, no real predicate, feels like the model cut itself off.
• Bad word swaps
You see odd synonyms that do not fit the sentence. You get phrases that sound close to normal English but not quite right.
• Weird endings
Some outputs ended in awkward, almost broken sentences. One test paragraph finished with something like “which causes to more being problematic to use.” That kind of thing sticks out.
If you want to hand the result straight to a client or a teacher without edits, I would not trust it. With manual editing you can fix a lot, but then you are doing the hard part yourself.
Limits, pricing, and data
The free tier felt tight.
• Free usage
You get roughly 300 words total. Not per document, total. After that, the site blocks further processing.
I ended up making three separate Gmail accounts to finish my normal test set. That alone tells you how limited the free option is.
• Paid plans
Starter: from $8.25 per month if billed yearly.
Unlimited: $26 per month.
Even on the “Unlimited” plan, each run is capped at 2,000 words. So longer reports or chapters need to be split and re-merged later.
• Refund policy
Purchases are non-refundable. So if you try it and dislike the results, there is no safety net.
• Data use
Text you submit is used for AI training by default. There is an opt-out, but you have to notice and set it.
On top of that, they reserve the right to use your company name in their promotional stuff unless you explicitly tell them not to. That part will bother some teams that care about privacy or brand control.
Comparison with Clever AI Humanizer
When I ran the same sort of benchmarking, I had better luck with Clever AI Humanizer. It scored stronger on the detectors I tested and did not hit me with hard paywalls the same way. It is fully free at the moment, which matters if you are experimenting or doing a lot of small runs.
Link for reference:
If your goal is to get cleaner passes on detectors without wrecking grammar, my experience put Clever AI Humanizer ahead of GPTHuman in both success rate and cost. GPTHuman feels more like an early draft tool that still needs heavy human cleanup and better alignment between its “human score” and what third party detectors see.
4 Likes
I had a similar experience to you, so here is what helped me figure out what was “me” and what was GPTHuman.
-
Prompts and config are not the core issue
GPTHuman behaves like a style filter, not a full model you steer with prompts. You can tweak wording a bit by telling it “make this more casual” or “more academic,” but that does not fix the odd grammar or detector issues. If you see broken sentences or weird synonyms, that is not your setup. That is the tool. -
Check consistency with a simple test
Try this small workflow:
• Take one short GPT output, around 200 words.
• Run it through GPTHuman on default settings.
• Run the same original text again, but change your prompt to “keep grammar correct and natural, do not change meaning.”
• Compare the two GPTHuman outputs side by side.
If both runs show the same types of errors, then your config is not the main factor. You are seeing model behavior. When I did this, the pattern of subject verb mismatches and odd word swaps stayed the same.
- Detector mismatch is normal for GPTHuman
You mentioned inconsistent outputs. A big part of that is detector variance.
My rough results across 10 samples:
• GPTHuman output
GPTZero flagged 9 of 10 as AI.
ZeroGPT flagged 4 of 10 as high AI, 6 as mixed or low.
So if you rely on GPTZero, your “good” runs inside GPTHuman will still look bad on the outside. That matches what @mikeappsreviewer saw, and I saw similar numbers. If you expect GPTHuman’s “human score” to mirror GPTZero, you will stay frustrated.
- How to make it less inconsistent in practice
What helped me stabilize quality:
• Use shorter chunks, 800 to 1,200 words max, even if the limit is higher.
Longer inputs increased the chance of grammar glitches for me.
• Run GPTHuman once, then run the result through a grammar checker.
I used a standard grammar tool and fixed obvious issues. This cut out the worst errors fast.
• Avoid stacking transformations.
Do not send text that already passed through another “humanizer” into GPTHuman again. It tends to compound mistakes.
This will not fix detector issues fully, but it keeps the output readable.
- If your main goal is detector performance
If your priority is passing common AI detectors rather than “content review,” GPTHuman feels unreliable. The non‑refundable pricing makes this worse if you are still experimenting.
For that specific use case, Clever Ai Humanizer gave me more consistent passes across GPTZero and ZeroGPT with fewer grammar problems. It is better suited if you want something closer to “paste in, get something detector friendly, do light edits.” You still need to review the text, but you spend less time fixing broken sentences.
- When GPTHuman still makes sense
I would keep GPTHuman for:
• Quick “make this sound less like raw GPT” edits on short pieces.
• Internal drafts where you do not care about detector scores.
• Situations where you will always do a full human edit after.
If your tests show wild swings per run, that is likely the tool, not your prompts. Treat it as a rough first pass, not a final content reviewer. If you want a more detector focused workflow, pairing your base model with Clever Ai Humanizer plus a grammar checker is more predictable.
Yeah, from what you’re describing, that “is it my prompt or the tool?” confusion is pretty typical with GPTHuman right now.
I’m mostly on the same page as @mikeappsreviewer and @cacadordeestrelas, but I’ll push back on one point: I don’t think spending a ton of time engineering prompts inside GPTHuman is worth it at all. It’s not really a “promptable” model in the way GPT is. Past super basic instructions, the tool kinda just does whatever its internal style filter is going to do.
Here’s how I’d look at it, more from a “what’s realistic to expect” angle than a “how do I fix it” one:
- Your config probably isn’t the main culprit
If you’re seeing:
- random subject verb errors
- clunky word swaps
- weird sentence endings
that’s not you misconfiguring anything. That’s pretty much the house style of GPTHuman right now. You can change tone a bit, but you can’t really get rid of that underlying behavior through prompts.
- The “human score” is marketing, not a benchmark
The internal “human score” is basically a vanity meter. It’s not calibrated to GPTZero, ZeroGPT, or anything else. So when you see “high human score” then a 100% AI flag on GPTZero, that isn’t a bug in your workflow. That’s just misaligned expectations.
Personally, I’d treat that score as noise. If your workflow depends on real detector performance, only the external tools matter.
- Inconsistency is the pattern
What you’re calling “inconsistent outputs” is almost the consistent thing about it:
- Some chunks look semi-okay
- Some are riddled with small but obvious mistakes
- Some get slaughtered by certain detectors no matter what you do
You can reduce the chaos a bit by controlling input length and not stacking multiple humanizers, but you’re never going to get rock-solid, repeatable behavior out of it the way you’d expect from a good LLM.
- How I’d actually use GPTHuman (if you must)
Not repeating the exact steps others posted, but in general I’d narrow it to:
- Only on short, disposable stuff
Think: social posts, rough drafts, internal notes. - Never as a “final pass” before submission
Use it earlier in the pipeline, then let a normal LLM or human do the final cleanup. - Don’t trust it to “fix” GPT, only to “distort” GPT
It’s pretty good at making text look different. It just isn’t great at making it better.
- If your goal is content review, not detector evasion
Honestly, if your main goal is “content review,” GPTHuman is kind of the wrong tool genre. It’s not a reviewer, it’s a rewriter with a weird style. For actual review you’re better off:
- Using a normal LLM to:
- highlight logical gaps
- check consistency
- improve clarity
- then, if you really need it, run the final through a humanizer
If your main concern is AI detection, then yeah, trying something like Clever Ai Humanizer makes more sense. It tends to keep grammar cleaner while still giving you different-enough phrasing, and it behaves more predictably with common detectors in practice. You’ll still need to eyeball and lightly edit, but you’ll spend less time un-doing its “creativity” compared to GPTHuman.
- How to tell if it’s worth keeping in your stack
Ask yourself:
- Are you okay doing a human edit on every GPTHuman output?
- Are you okay with external detectors sometimes screaming “AI” even when its own score says you’re safe?
- Are you okay paying for that, given the non‑refundable thing?
If you’re answering “no” to two or more of those, I’d stop trying to debug your setup and just accept that the tool’s behavior doesn’t match what you need. At that point it’s not a configuration problem, it’s a product fit problem.
TL;DR: it’s not that you’re “using the wrong prompts.” GPTHuman is doing what GPTHuman does. If you want something closer to “paste → passable, human-like text with fewer landmines,” pairing a normal LLM for review plus a pass through something like Clever Ai Humanizer is a more sane workflow right now.
Short version: your setup is probably fine; your expectations of what GPTHuman can realistically do are not.
Instead of rehashing what @cacadordeestrelas, @sternenwanderer, and @mikeappsreviewer already covered, I’d zoom out and ask a different question:
What job are you hiring this tool to do?
Right now you’re mixing three roles:
- AI‑detector evasion
- Style “humanization”
- Actual content review / quality control
GPTHuman is only halfway decent at #2, pretty shaky at #1, and essentially not built for #3 at all. That is why your prompts feel like they “don’t work.” You are asking it to be a reviewer and a detector shield when it is structurally a noisy rewriter.
Where I disagree a bit with others
Some folks said “just accept it as a style filter.” I partly disagree. If a style filter routinely introduces subject verb errors and fragment sentences, it is not merely a style filter; it is a liability in any serious workflow. Treating it as a harmless first pass is fine only if:
- You never send its output directly to clients / teachers
- You always plan on a full human or high‑quality LLM edit after
Otherwise, the tool is not neutral. It can actively downgrade your text.
How to diagnose your situation without more prompt tinkering
Instead of testing different instructions, test roles:
-
As a reviewer
Give GPTHuman a paragraph and ask it to “comment on clarity and correctness without rewriting.”- If it still rewrites aggressively or gives vague feedback, it simply cannot serve as a reviewer.
- That is not a config problem; that is product scope.
-
As a style humanizer
Feed it a paragraph that is already human written and clean.- If the output comes back with worse grammar or awkward synonyms, then the tool is damaging good text just to look different.
- In that case, it should never touch final‑draft material.
-
As a detector helper
Pick one external detector that actually matters to you and standardize on it.- If GPTHuman consistently fails on that detector even when its internal “human score” is high, treat that internal score as cosmetic and stop trying to make them line up.
This way, you are not debugging prompts. You are deciding which roles GPTHuman can safely play in your stack, if any.
Where Clever Ai Humanizer fits in
If your primary pain is “I need AI‑written content to read naturally and not be shredded by detectors,” then Clever Ai Humanizer is closer to the right tool genre. I would not call it perfect, but it tends to behave more like a strong paraphraser than a glitchy style mutator.
Pros of Clever Ai Humanizer
- More stable grammar in typical use
- Less aggressive nonsense synonym swaps
- Friendlier to quick workflows: paste, transform, light human edit
- Better alignment in practice between its outputs and common detector behavior compared to what people report from GPTHuman
Cons of Clever Ai Humanizer
- Still not a real “content reviewer,” so you need a separate tool or human for logic and structure
- Can occasionally over soften or over generalize, which matters for technical or very precise writing
- Detector outcomes are still probabilistic, not guaranteed, so you cannot treat it as a magic bypass switch
Compared to what @cacadordeestrelas, @sternenwanderer, and @mikeappsreviewer described, I would say:
- They are right that your prompts are not the main culprit.
- I am a bit stricter: I would not trust GPTHuman at any stage where quality actually matters, except as a quick distortion filter for low‑stakes drafts.
- If your goal is genuine “content review,” use a solid LLM for analysis and revision, then optionally run the final through something like Clever Ai Humanizer for detector friendliness, and only if your context really needs that.
If you stop trying to make GPTHuman be a reviewer or a detector oracle and only let it act as a disposable rewriter on noncritical text, the “is it me or the tool?” confusion disappears. It is the tool.